SQL Server - クエリーでの重複データ削除のコツ
クエリーでの重複データ削除する際のコツをご紹介
データベースの設計していると、このテーブルの中で、
「このカラムと、このカラムと、このカラムと、このカラムと、このカラムの値のコンビネーションはユニークになる前提。」
というような、キーとなるカラム達が出てきたりしますよね。
わかっているならば、UNIQUE 制約をつけておくべきだと思います。
想定外のデータをインサートしようとした時点でエラーが出るので、保存されているデータは常に想定の状況になっていることが保証されていて、不具合が起こりにくくなるのは明らかです。
ここでは UNIQUE 制約をつけてない状況で、想定外の重複データができてしまった場合に、1 つを除いて削除する時のコツをご紹介したいと思います。
ROW_NUMBER() を使って、残したいデータを特定しよう
重複データでどのデータを残すか特定する際に便利なのが ROW_NUMBER() ファンクションです。
ROW_NUMBER() OVER (PARTITION BY [カラム1], [カラム2],... ORDER BY [カラムA], [カラムB],...)
ROW_NUMBER() ファンクションの PARITION BY にキーとなるカラムを全て指定します。 そして ORDER BY に残したいレコードが一番上にくるように指定します。
たとえば、電車の料金入っているテーブルで出発地、目的地、座席クラス、日付がキーとなる情報で、一番高い料金のレコードを残したいのであれば以下のように指定します。
ROW_NUMBER() OVER (PARTITION BY [出発地], [目的地], [座席クラス], [日付] ORDER BY [料金] DESC) AS RowNo
もし一番最初に作られたデータを残したいのであれば次のような感じです。
ROW_NUMBER() OVER (PARTITION BY [出発地], [目的地], [座席クラス], [日付] ORDER BY [作成日]) AS RowNo
残すレコードがどれでもいい場合は ORDER BY には何を指定しても良いです。
このようにすると、残したいデータの RowNo が以下のように 1 になります。
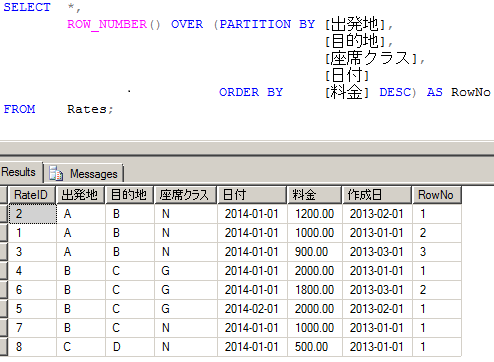
取得した RowNo と プライマリーキーで重複データを削除する
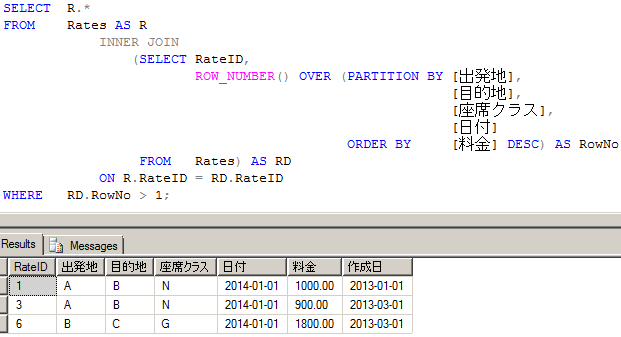
上記のテーブルでは RateID がプライマリーキーです。 ですので、RowNo > 1 の RateID を持つレコードを削除すれば OK です。
たとえば、 以下のような感じで Select 文で削除するレコードを確認してから、 SELECT R.* を DELETE R に書き換えて実行するのもひとつの方法です。
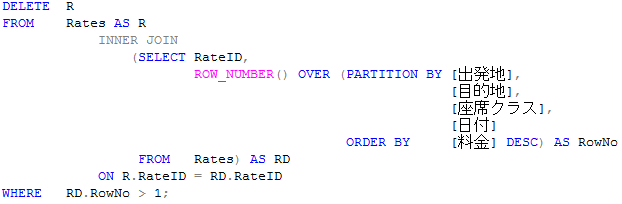
データ量が多いテーブルに対して実行する場合は、以下のように一度削除する RateID 持つ Temp テーブルを作ったほうが良いかもしれませんね!
